Retrieval-Augmented Generation (RAG) with Elixir
This is my initial attempt at implementing RAG in Elixir. My goal is to develop a system similar to PrivateGPT by gaining a deeper understanding of the concepts and improving chunking and metadata techniques. For this project, I intentionally avoided using LangChain or OpenAI to explore the foundational aspects of RAG.
Checkout the code implementation here. The code is at a very alpha and just shows a simple RAG. I plan to develop this code further and want to build something similar to PrivateGPT in Elixir.
Retrieval-Augmented Generation (RAG) is a technique that enables Large Language Models (LLMs) to incorporate relevant and up-to-date information, allowing the LLM to address contexts it hasn’t been specifically trained on. RAG extends the powerful capabilities of LLMs into specific domains without the need for retraining, making it a cost-effective approach to enhancing LLM outputs, ensuring they remain relevant, accurate, and useful across various contexts.
Image Source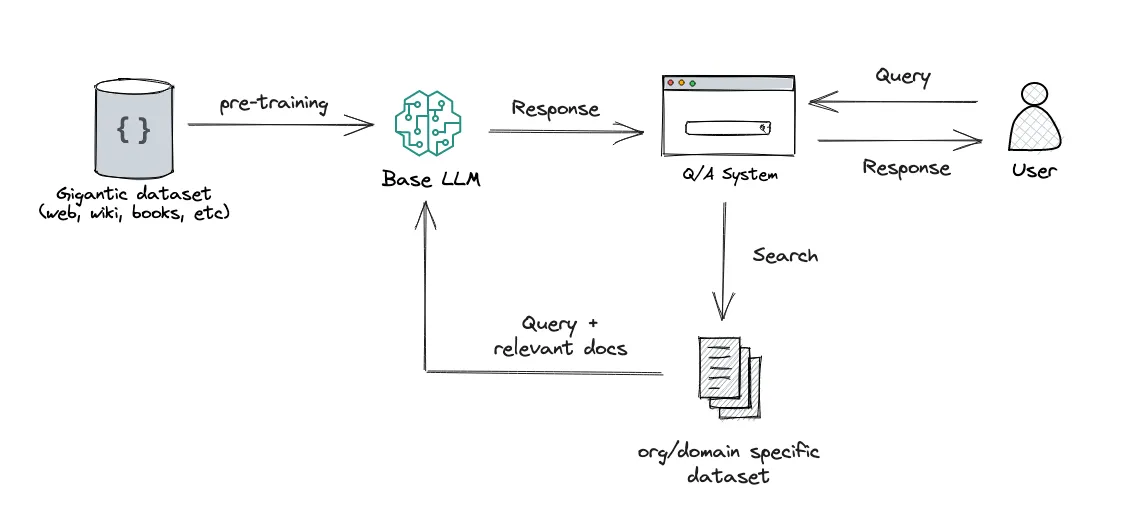
RAG is a multi step process;
- Document Ingestion
- Chunking
- Embedding
- Vector Database
- Retrival & Query Processing
- Generation & Output
Document Ingestion (Input)#
Document ingestion involves using a HTML document, a PDF, an image, or an audio file as input for an LLM model. For this project, I used the Reddit S1 filing as a knowledge base, providing prompts and questions based on it. For this initial attempt, I didn’t focus on tables and pictures within the S1 filing, as I aimed to develop a basic system capable of replying using the knowledge base.
To read a PDF file, libraries such as pdftotext can be used. Here’s a simple command to read the file:
# Not using stream for now
{:ok, contents} = File.read("/priv/static/s1-file.md")
# OR
{:ok, response} = HTTPoison.get("https://gist.githubusercontent.com/theshapguy/d8633451460dac8a6cf6f0cf75a00f74/raw/a796d8af1452caa5d6857e67d40041a2ccaa3b14/RedditS1_RAG.txt")
_contents = response.body
Chunking#
Chunking converts a large corpus into manageable, byte-sized content, improving retrieval efficiency and relevance by enabling the system to fetch specific, pertinent sections rather than entire documents.
By breaking larger texts into smaller chunks, we can selectively feed the most relevant pieces into the LLM, maximizing the use of available context and enabling the model to work with larger amounts of information than its default context window would allow. Ideally, each chunk should contain text about a specific topic, concept, or idea.
def chunk_document(content \\ html_input()) do
TextChunker.split(content)
|> Enum.map(& &1.text)
end
Findings#
- Without chunking, the LLM model struggles to find the right information; larger context windows increase hallucinations.
- Smaller chunks capture more granular semantic information, while larger chunks retain more context.
- Summaries can be used instead of the whole document, speeding up retrieval and enhancing meaningful content retrieval.
- Chuking styles
Embedding & Vector Database#
Imagine you have a big box of different toys. Each toy is special and unique in its own way. Now, let’s say you want to organize these toys so you can easily find similar ones. Embeddings are like giving each toy a special set of numbers that describe it. These numbers tell us things about the toy without us having to look at it directly. For example:
- A toy car might get numbers like: [4, 2, 1] (4 for “has wheels”, 2 for “made of metal”, 1 for “small size”)
- A stuffed animal might get: [0, 0, 3] (0 for “no wheels”, 0 for “not metal”, 3 for “soft and cuddly”)
Now, when you want to find toys that are similar, you can just look at their numbers. Toys with similar numbers are probably alike in real life too!
Embeddings turn words, sentences, or documents into a vector list of a certain dimension, allowing prompts (queries) to be compared quickly. These embeddings are stored in a vector database such as ChromaDB or PGVector for retrieval when a query is made.
Findings#
- I found that most people are using ChromaDB, however I preferred to use PGVector as it allowed me to iterate faster and I didn’t have to learn about another technology.
- Multiple models can be used for embedding; I used BAAI/bge-small-en-v1.5 for local testing. Local models can be as powerful as OpenAI’s embeddings.
- Make sure to embed the document and retrive with the same model and vector size.
defmodule Agents.Repo.Migrations.CreateSections do
use Ecto.Migration
def change do
execute "CREATE EXTENSION IF NOT EXISTS vector"
create table(:sections) do
add :embedding, :vector, size: 384
add :chunk, :text
add :metadata, :map
timestamps(type: :utc_datetime)
end
create index("sections", ["embedding vector_cosine_ops"], using: :hnsw)
end
end
schema "sections" do
field :chunk, :string
field :metadata, :map
field :embedding, Pgvector.Ecto.Vector
timestamps(type: :utc_datetime)
end
def embed_chunks(chunk) do
%{embedding: embedding} =
Nx.Serving.batched_run(SentenceTransformer, chunk |> String.trim())
Sections.create_section(
%{"chunk" => chunk |> String.trim(), "embedding" => embedding}
)
end
Retrival & Query Processing#
When querying, such as “What are the risk factors for Reddit?”, the first step is converting the text into a vector embedding. We use the same embedding model and vector size for both the query and document chunks for accurate similarity comparisons.
Vector Search Process#
Once we have the query embedding, we perform a vector search to find similar chunks of data. This search is based on the principle that semantically similar texts will have similar vector representations. We typically use cosine similarity to measure how close two vectors are. Cosine similarity values range from -1 to 1, with 1 indicating perfect similarity. For our Reddit risk factors query, we might find chunks discussing various business risks, user engagement challenges, or regulatory concerns. Vector search is incredibly efficient compared to traditional text search, allowing us to quickly sift through millions of chunks to find the most relevant ones.
In PostgresSQL using Ecto/Elixir there is already a query function for this.
Reranking with Cross-Encoders#
After the initial vector search, we employ a reranking step using a cross-encoder. In our case, we use the cross-encoder/ms-marco-MiniLM-L-6-v2 model. Unlike the initial embedding model, which encodes the query and documents separately, the cross-encoder considers the query and each potential chunk together. The cross-encoder generates a single, unified representation of the paired texts by considering the interactions between them at each layer of the transformer. This allows for a more nuanced understanding of relevance, often leading to improved ranking. While cross-encoders provide better accuracy, they are computationally more expensive. That’s why we use them for reranking a smaller set of initially retrieved chunks rather than for the initial search.
# In postgressql we can do a vector search using max_inner_product rather than cosine similarity
# under the hood (same thing)
def search_document_embedding(embedding) do
from(s in __MODULE__,
select: {s.id, s.chunk},
order_by: max_inner_product(s.embedding, ^embedding),
limit: 20
)
|> Repo.all()
end
Generation & Output#
Once we have all the relevant context from the vector database, we can create a prompt within a prompt window. We collect all the relevent context and create a prompt as such below.
prompt = """
[INST] <<SYS>>
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you do not know the answer, just say that you don't know. Use two sentences maximum and keep the answer concise.
<</SYS>>
Question: #{question}
Context: #{context}[/INST]
"""
client = Ollama.init()
Ollama.completion(client,
model: "llama3.1",
prompt: prompt
)
Conclusion#
In conclusion, Retrieval-Augmented Generation (RAG) with Elixir is a powerful technique that enhances the capabilities of Large Language Models (LLM) by incorporating relevant and up-to-date information. By leveraging document ingestion, chunking, embedding, vector database, retrieval, query processing, and generation, RAG enables LLMs to provide contextually accurate and useful responses without the need for retraining.
Overall, I found understanding RAG systems to be very easy. However, managing the pipelines and moving this code into production will take further readings. Firstly, I’ll looking into metadata filtering because that allows us to find correct chunks further. Then, I’ll data ingestion as this is the step that allows us to represent the data better. i.e use data from tables, use data from pictures hence this is the most cruicial state in the RAG pipeline.
While building this “PrivateGPT”, I’ll use using Task.async, Genservers so that all processing can take place in the background. With Elixir excelling at background and concurrect tasks it is the best fit for this job.